This post will describe how can we ingest the geospatial data into Apache Solr for search and query.
The pipeline is built with Apache Spark and Apache Spark Solr connector.
The purpose of this project is to ingest and index data for easy search.It has support fo SpatialSearch nearest neighbors or full-text by name.Apache Spark is used for distributed in memory compute , transform and ingest to build the pipeline.
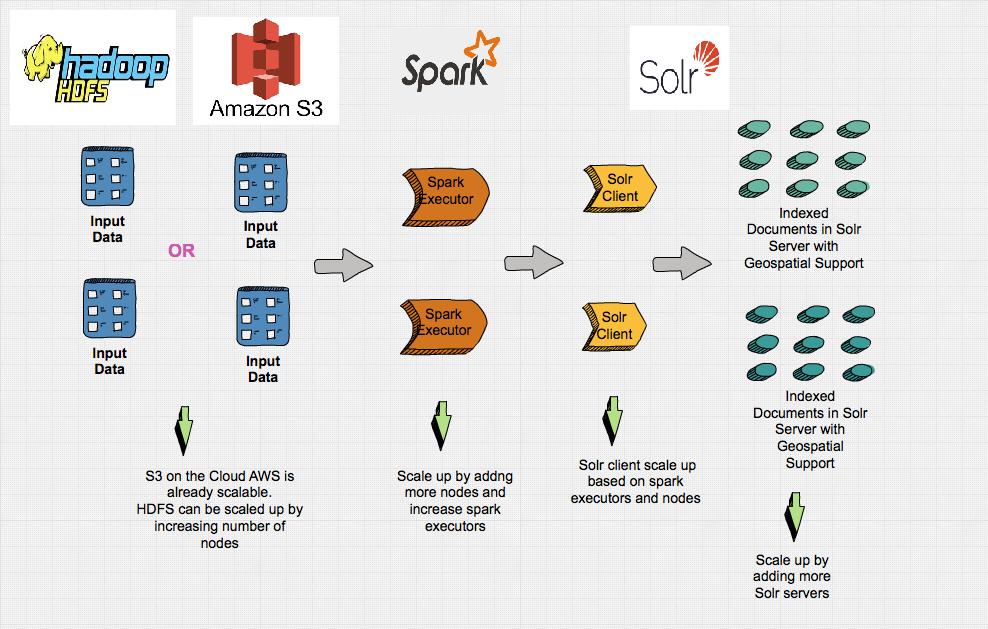
Apache Solr is used for storage and indexing can be configured in cloud mode (Multiple Solr servers) can be easily scaled up by increasing server nodes.
The Apache Solr collection (table name sql equivalent) can be configured with shards (no of partitions) and replicas (fault tolerance)
The requirement to handle schema evolution can be done by Solr Managed Schema Configuration
The id attribute which is derived from geonameid will take care of updating the collection for future updates and schema evolution as describe above.
The overall high level architecture of the pipeline will look something like described in the image below.
The data we’re working with is open data from Geonames.org, specifically a compressed dataset of global cities with greater than 1000 population.It’s small enough to be inspected, the .tsv data fields are described in plain-text form at the bottom of the index page.
The source is available on github. Please feel free to download and experiment with it. The small presentation is available here.
The Makefile is provided to run the whole pipeline end to end with Docker Compose.
.PHONY: build build: sbt clean assembly up: docker network create geo-net docker-compose -f build/docker-compose.yml up -d delete: curl -X GET 'http://192.168.99.100:8983/solr/admin/collections?action=DELETE&name=geo_collection' create: curl -X GET 'http://192.168.99.100:8983/solr/admin/collections?action=CREATE&name=geo_collection&numShards=1' curl -X POST -H 'Content-type:application/json' -d '@build/geo_collection.json' 'http://192.168.99.100:8983/solr/geo_collection/schema' down: docker-compose -f build/docker-compose.yml down docker-compose -f build/docker-compose-spark-submit.yml down docker network rm geo-net run: docker-compose -f build/docker-compose-spark-submit.yml build docker-compose -f build/docker-compose-spark-submit.yml up reload: curl -X GET 'http://192.168.99.100:8983/solr/admin/collections?action=RELOAD&name=geo_collection'
- Compile Scala Code :
make build
- Run the Docker Containers :
This will spin up 1 Solr instance in cloud mode with embedded Zookeeper . 1 Spark Master Instance and 1 Spar Worker Instance. The definition for docker compose are provided in build directory.
make up
- Create Collection in Solr with Schema :
make create
- Geo Collection Schema :
{
"add-field": [
{
"name": "administrativeLevel1",
"type": "string",
"docValues": true,
"multiValued": false,
"indexed": true,
"stored": true
},
{
"name": "administrativeLevel2",
"type": "string",
"docValues": true,
"multiValued": false,
"indexed": true,
"stored": true
},
{
"name": "countryCode",
"type": "string",
"docValues": true,
"multiValued": false,
"indexed": true,
"stored": true
},
{
"name": "latitude",
"type": "pfloat",
"docValues": true,
"multiValued": false,
"indexed": true,
"stored": true
},
{
"name": "location",
"type": "location",
"docValues": true,
"multiValued": false,
"indexed": true,
"stored": true
},
{
"name": "longitude",
"type": "pfloat",
"docValues": true,
"multiValued": false,
"indexed": true,
"stored": true
},
{
"name": "name",
"type": "string",
"docValues": true,
"multiValued": false,
"indexed": true,
"stored": true
}
]
}
Prerequisite : Make sure you download the data file zip file and unzip it and put it inside the build/data folder. Adjust the IP address as per your environment. I am running docker on Mac OS so the virtual machine IP is 192.168.99.100
- Run the ingestion pipeline :
make run
The above command will build the simple docker container and connect to the geo-net docker network copy the assembled jar into the container to pickup the code changes and executes the spark-submit command.
Note : After the job completes please make sure to reload the collection otherwise sometimes I was having issues no results being returned back
make reload
The simple Scala code which gets deployed :
Note : Change the zkhost to localhost:9983 if you running locally without container. To run locally follow Setup section on README.md
package com.geoname
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.{SaveMode, SparkSession}
object IndexGeoData {
def main(args: Array[String]): Unit = {
// Running in simple standalone mode for POC and providing all the cores
// Production mode master will be set to YARN or MESOS // Distributed resource manager scheduler
val sparkConf =
new SparkConf()
//.setMaster("local[*]")
.setAppName("index_geo_data")
val sparkSession: SparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
// Define Schema to match the source data as described here at the bottom of the page
val geonameSchema = StructType(
Array(
StructField("geonameid", IntegerType, false),
StructField("name", StringType, false),
StructField("asciiname", StringType, true),
StructField("alternatenames", StringType, true),
StructField("latitude", FloatType, true),
StructField("longitude", FloatType, true),
StructField("fclass", StringType, true),
StructField("fcode", StringType, true),
StructField("country", StringType, true),
StructField("cc2", StringType, true),
StructField("admin1", StringType, true),
StructField("admin2", StringType, true),
StructField("admin3", StringType, true),
StructField("admin4", StringType, true),
StructField("population", DoubleType, true),
StructField("elevation", IntegerType, true),
StructField("gtopo30", IntegerType, true),
StructField("timezone", StringType, true),
StructField("moddate", DateType, true)
))
// Load the tab separated files
// Single file or multiple files can be loaded
// We can provide directory path instead of path to file name
// It can also be loaded from HDFS / S3 etc..
// The data can be loaded from local file system as in in this example.
val geonamesDF = sparkSession.read
.option("header", "false")
.option("inferSchema", "false")
.option("delimiter", "\t")
.schema(geonameSchema)
.csv(args(0))
// 1. Log4j Logging --> Log stash --> elastic search --> Kibana/Grafana
// 2. Amazon cloud watch agent
//Apply Primer Transformation
val primerDF = geonamesDF.select(
col("geonameid").as("id"),
col("name"),
col("latitude"),
col("longitude"),
col("country").as("countryCode"),
col("admin1").as("administrativeLevel1"),
col("admin2").as("administrativeLevel2"),
concat_ws(",", col("latitude"), col("longitude")).as("location")
)
// 1. Log4j Logging --> Log stash --> elastic search --> Kibana/Grafana
// 2. Amazon cloud watch agent
// 3. Change the zkhost to localhost:9983 if you running locally without container.
val options =
Map("zkhost" -> "solr:9983", "collection" -> "geo_collection")
//Index to Solr for Query and Search
//primerDF.show()
primerDF.write
.format("solr")
.options(options)
.mode(SaveMode.Overwrite)
.save()
// 1. Log4j Logging --> Log stash --> elastic search --> Kibana/Grafana
// 2. Amazon cloud watch agent
//val df = sparkSession.read.format("solr").options(options).load
//df.show()
sparkSession.stop()
}
}
- Now lets query the data:
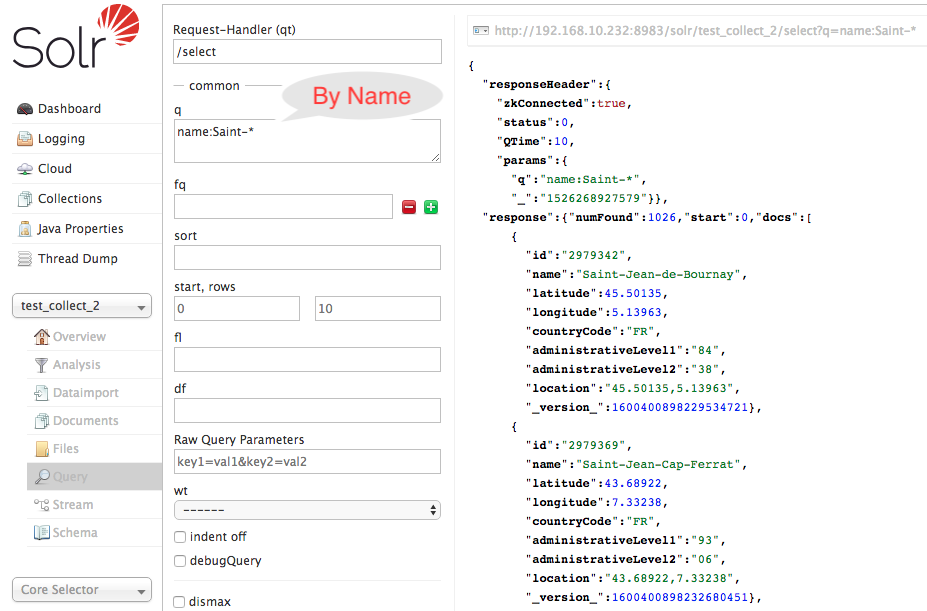
- Search By Name :
- Command Line:
curl "http://192.168.99.100:8983/solr/geo_collection/select?q=name:Saint-*"
- Solr UI:
- Command Line:
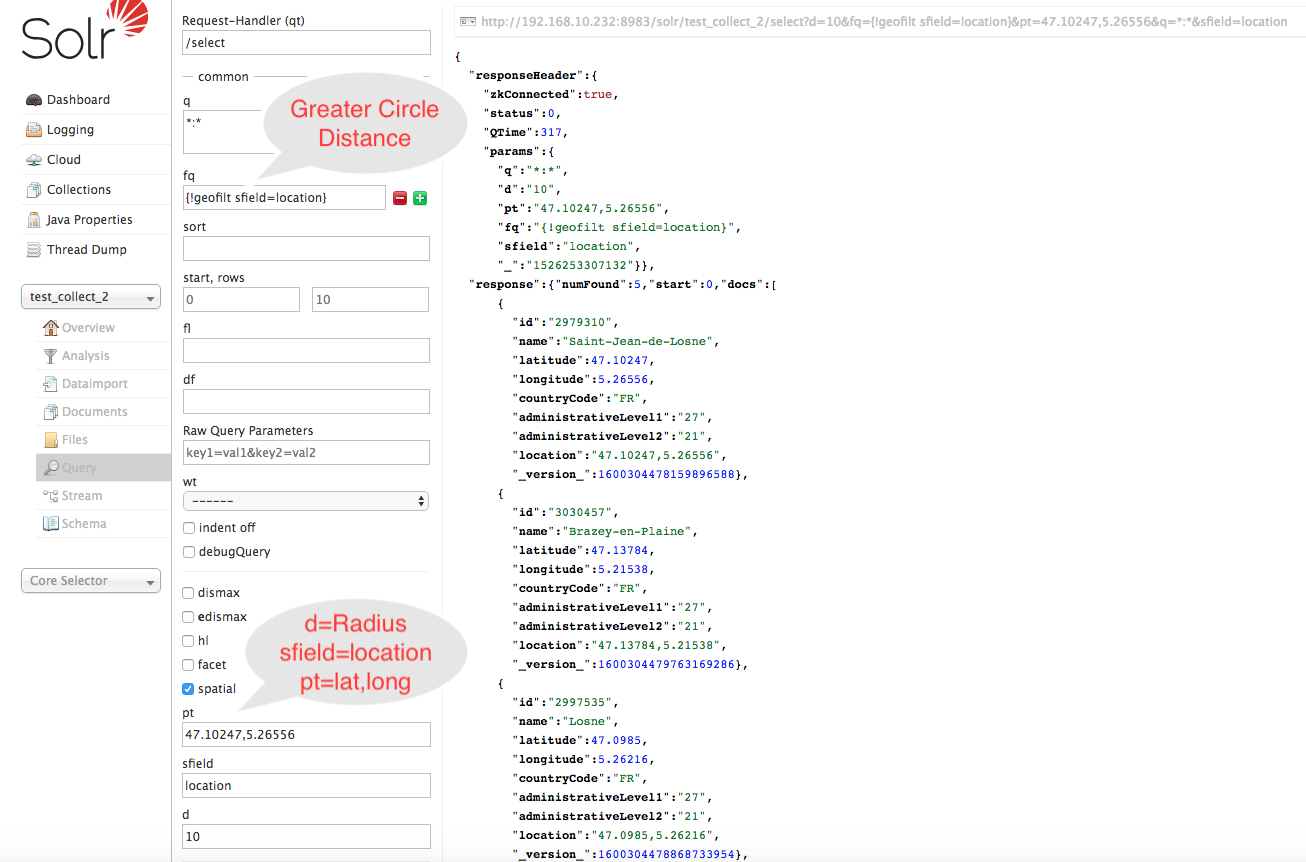
- Search Nearest Neighbors By Great Circle Distance Box geofilt and Filter By Radius 10 :
- Command Line
curl "http://192.168.99.100:8983/solr/geo_collection/select?d=10&fq=\{!geofilt%20sfield=location\}&pt=47.10247,5.26556&q=*:*&sfield=location" - Solr UI:
- Command Line
- Search Nearest Neighbors By Bounding Box Distance bbox and Filter By Radius 5 :
- Command Line
curl "http://192.168.99.100:8983/solr/geo_collection/select?d=5&fq=\{\!bbox%20sfield=location\}&pt=47.10247,5.26556&q=*:*&sfield=location" - Solr UI:
- Command Line

- Stop the ingestion pipeline :
make down
All the data will be lost, containers will be removed because I have not setup the docker volume for persistence which can be easily done in solr docker container setup.
Theres is a lot you can do and explore as described here .
Enjoy Reading!!!
